Covid-19 Tweet Classifier with Neural Networks (Kaggle Dataset)
Tools used: Python 3, TensorFlow/ Keras, NLTK, Numpy and Jupyter Notebook
Abstract
The goal of this project is to create a classifier which takes in tweets and classifies them as one of the following sentiments: extremely negative, negative, neutral, positive and extremely positive.
Using this Kaggle dataset as our training data, we have over 40,000 labelled Covid-19-based-tweets. Using this as our training data, we can train our feed-forward based Neural Network.
Requirements
There are a few Python 3 packages requried for this tool:
- pip install keras - Keras is a high-level API which sits on top of TensorFlow. This will be used to create, train and test our Neural Network.
- pip install tensorflow - even though we are using Keras, TensorFlow will still be required to run in the background.
- pip install numpy - we'll be using NumPy to format our data to be compatible with the Neural Network and various other reasons.
- pip install nltk - we will need to clean and transform our Tweets. NLTK is Python's most advanced natural language processing (NLP) library.
- pip install jupyterlab (Optional) - Jupyter Notebook will be our coding environment of choice, allowing us to structure our code and functions more easily.
You will need to download NLTK's data (corpora, models, functions, etc.).
Once NLTK is installed, you will need to download the NLTK dataset (download all).
import nltk
nltk.download()Process Outline
There are 6 main steps we need to go through to create our classifier. Most of the work here will revolve around cleaning and formatting our data for our Neural Network.
- [Function] Clean tweets
- Create a unique word lexicon
- [Function] Convert training tweets into numerical arrays (features)
- Balance our training dataset
- Create and train our Neural Network model
- Using our Neural Network model
1) Clean Tweet Function
The first step in this process is the create a function that will clean our tweets. Each tweet we have could contain links, hashtags, usertags or foreign languages. We only want to focus on the words the user used which could affect the tweet's sentiment.
Here, we are going to use NLTK's list of stopwords, Tweet Tokenizer and the WordNet lemmatizer.
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
stop_words = set(stopwords.words('english'))
tTokenizer = TweetTokenizer()
lemmatizer = WordNetLemmatizer()Firstly, we tokenize each tweet into a list which seperates each word. For each word, we check for links, user-tags, hashtags or if the word is in our list of stopwords, and remove any which are.
We then remove all punctuation and lowercase each word. The lemmetizer is used to group similar words with share the same meaning into one word, as well as granulating each word. We do this as we don't require the past/ future tense of each word, nor the context of each word. Our Neural Network simply will look at each word individually and weight against which words are used in conjunction with each other.
def process_tweets(tweet):
tweet_words = tTokenizer.tokenize(tweet)
cleaned_tweet_words = []
for word in tweet_words:
if 'https' in word or '#' in word or word in stop_words:
pass
else:
punctuation_cleaned = word.translate(str.maketrans('', '', string.punctuation)).lower()
lemmatized_word = lemmatizer.lemmatize(word)
cleaned_tweet_words.append(lemmatized_word)
return cleaned_tweet_wordsThis function returns a list of words which contain 'meaning', for each tweet.
2) Create a Unique Word Lexicon
Our method for creating our featureset revolves around a lexicon, which contains all of the unique words in our training samples. This will be used to convert each tweet into one-hot-like arrays (features).First, we process every tweet using our tweet cleaning function and appear all words to a large list. We then use Counter() to get the count of each word. We set two thresholds for a max and min amount of appearances a word should have to be part of our lexicon.
for tweet, sentiment in tqdm(uncleaned_data):
for word in process_tweets(tweet):
all_words.append(word)
all_words_counted = Counter(all_words)
final_lexicon = []
LEXICON_MAX_WORDS = 1000
LEXICON_MIN_WORDS = 50
for word in all_words_counted:
if LEXICON_MAX_WORDS > all_words_counted[word] > LEXICON_MIN_WORDS:
final_lexicon.append(word)We don't want words which appear too many times (LEXICON_MAX_WORDS) as these will tend to be 'meaningless' for our specific goal (positive/ negative sentiment). We also dont want words which appear too few times, which tend to be words which may have been misspelt or wont affect our model. Doing this will also help reduce the size of our lexicon, which therefore means our features will also be reduced in size.
3) Convert training tweets into numerical arrays (features)
Using our lexicon, we will convert each tweet into a NumPy array. Here, a one-hot style array will be created based on the words of each tweet and the index of the words based on the lexicon.
For example, if our lexicon has 5 words, the following tweet will be converted into a NumPy array:
# example lexicon and featureset
lexicon = ['good', 'bad', 'tea', 'phone', 'car']
tweet = 'I like to drink tea while on my phone in my car.'
tweet_feature_array = np.array([0, 0, 1, 1, 1])To process all our tweets into our one-hot-like arrays, we first need to make a NumPy array with the length according to the number of words in our lexicon.
tweet_array = np.zeros(lexicon_len)We then run each tweet through our tweet cleaner and check if there are at least 4 clean words in the tweet.
np.put() allows us to insert a '1' into the tweet array at the index position of the word, accoridng to the lexicon.
np.put(tweet_array, final_lexicon.index(word.lower()), 1)Finally, we split the tweet arrays (features) and sentiments (labels) into separate lists. The full function is as follows:
import numpy as np
sentiment_index = {'Extremely Negative': 0,
'Negative': 1,
'Neutral': 2,
'Positive': 3,
'Extremely Positive': 4}
def create_features_and_labels(uncleaned_data, final_lexicon):
lexicon_len = len(final_lexicon)
full_tweet_features = []
for tweet, sentiment in tqdm(uncleaned_data):
tweet_array = np.zeros(lexicon_len)
processed_tweet_words = process_tweets(tweet)
if len(processed_tweet_words) >= 4:
for word in process_tweets(tweet):
if word.lower() in final_lexicon:
np.put(tweet_array, final_lexicon.index(word.lower()), 1)
full_tweet_features.append([tweet_array, sentiment_index[sentiment]])
x_train = [tweet_array for tweet_array, sentiment in full_tweet_features]
y_train = [sentiment for tweet_array, sentiment in full_tweet_features]
return x_train, y_train4) Balance Our Training Dataset
We will need to make sure we have an equal number of samples for each sentiment, in our training set. This will help avoid our neural network over-fitting or being biased towards certain sentiments (outputs).
Now that we have our x_train and y_train sets...
x_train, y_train = create_features_and_labels(uncleaned_data, final_lexicon)we need to check which label in our training set appears the least amount of times. With this, we can make the sample sizes of every other label the same.
sentiment_lengths = Counter(y_train)
lowest_sentiment = min(sentiment_lengths, key=sentiment_lengths.get)With, we can now loop through each label in our y_train dataset and append each tweet and it's corresponding label to our balanced_data list until we have reached the length of the lowest_sentiment.
Finally, we use a simple random.shuffle() to shuffle all our features and labels. This is important so that our Neural Network model doesn't fit to any patterns around a specific order of our training data.
sentiment_lengths = Counter(y_train)
lowest_sentiment = min(sentiment_lengths, key=sentiment_lengths.get)
balanced_data = []
for sentiment in sentiment_index:
setiment_count = 0
for indx, row in enumerate(y_train):
if row == sentiment_index[sentiment]:
balanced_data.append([x_train[indx], np.array(row)])
setiment_count += 1
if setiment_count >= sentiment_lengths[lowest_sentiment]:
break
random.shuffle(balanced_data)
x_train = [tweet_array for tweet_array, sentiment in balanced_data]
y_train = [sentiment for tweet_array, sentiment in balanced_data]We want to save our features, labels and our lexicon to NumPy files. This will save time processing the tweets for the futures.
np.save('x_training.npy', x_train)
np.save('y_training.npy', y_train)
np.save('final_lexicon.npy', final_lexicon)5) Create and Train Our Neural Network Model
Now that we have our training data (features (X's) and labels (Y's)), a simple feed-forward Deep Neural Network will be used to create our classifier.
import tensorflow.keras as keras
import tensorflow as tf
import numpy as np
x_train = np.load('x_training.npy', allow_pickle=True)
y_train = np.load('y_training.npy', allow_pickle=True)We also need to reshape our x_train set, so that it is in the correct format for our Neural Network:
x_train = x_train.reshape(len(x_train), len(x_train[0]), 1)For our network, the Sequential model will be used. This is a simple model which works well for plain stacks of layers which have a consistent input and output.
We start by flattening with the first layer. This isn't too important for this specific project, as each tweet is a 1 x len(lexicon) x 1, however it can help when trying to use multi-dimensional datasets. This will turn an input with a shape of 28 x 28 into a shape of 784 x 1.
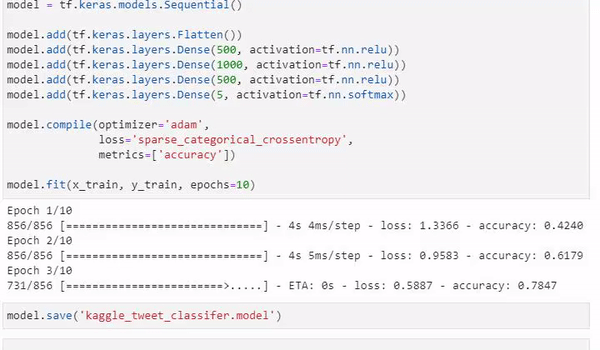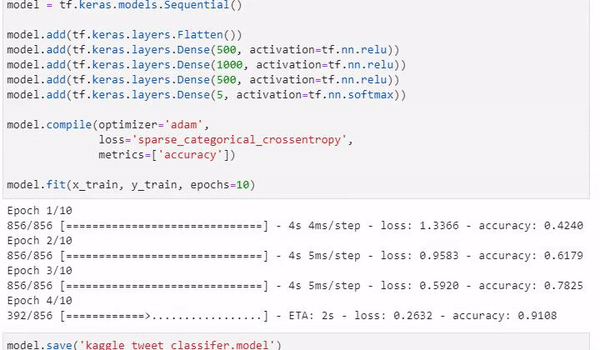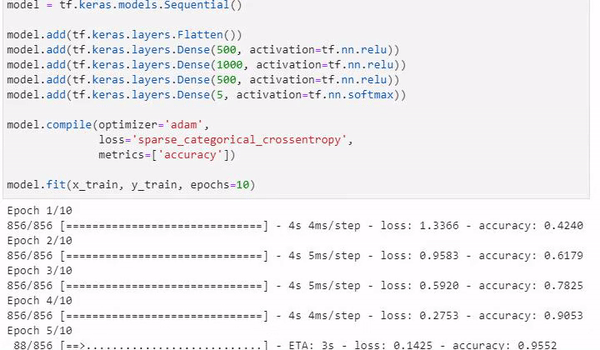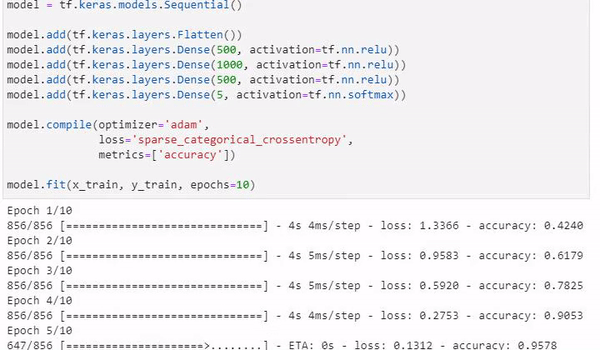
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten())Now, we add 3 Dense layers to our network. Each layer will have 500, 1000 and 500 nodes respectively. The number of layers and nodes required tends to be quite subjective and dependant on the type of data you're working with. After testing out different sizes, I simply found this one the have optimal results.
model.add(tf.keras.layers.Dense(500, activation=tf.nn.relu))
model.add(tf.keras.layers.Dense(1000, activation=tf.nn.relu))
model.add(tf.keras.layers.Dense(500, activation=tf.nn.relu))Our final layer will be our output layer. Here, we are using another dense layer with 5 nodes (as we have 5 outputs).
model.add(tf.keras.layers.Dense(5, activation=tf.nn.softmax))To compile our model, we are going to be using the 'adam' optimizer, sparse categorical corssentropy for our loss function and 10 epochs.
Epochs is the number of times our network will run through our data. 10 epochs means it will going over our dataset 10 times, each time adjusting the weights of each input to each neuron, hopefully decreasing loss (which in turns increases accuracy).
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10)After running our model, we are left with a promising accuracy of 97.8%
...
Epoch 7/10
856/856 [==============================] - 4s 4ms/step - loss: 0.0780 - accuracy: 0.9755
Epoch 8/10
856/856 [==============================] - 3s 4ms/step - loss: 0.0627 - accuracy: 0.9795
Epoch 9/10
856/856 [==============================] - 3s 4ms/step - loss: 0.0568 - accuracy: 0.9815
Epoch 10/10
856/856 [==============================] - 3s 4ms/step - loss: 0.0671 - accuracy: 0.9774Finally, we will want to save our model, ready for usage!
model.save('covid19_tweet_classifer.model')6) Classifying Tweets with Our Neural Network
With our trained model, we will be able to pass in tweets and the sentiment will be outputted.
To start, lets import our testing dataset, as well as our lexicon and trained model:
import csv
import numpy as np
with open('Corona_NLP_test.csv', newline='') as f:
reader = csv.reader(f)
uncleaned_test_data = list(reader)[1:]
final_lexicon = list(np.load('final_lexicon.npy', allow_pickle=True))
model = tf.keras.models.load_model('covid19_tweet_classifer.model')Lets process our testing tweets with the same method as we did for our training data:
x_test, testing_tweets = create_features_and_labels(uncleaned_test_data, final_lexicon)
x_test = x_test.reshape(len(x_test), len(x_test[0]), 1)Now we can use model.predict() to pass our tweets through the trained model and classify each one:
predictions = model.predict(x_test)Let's see some examples using np.argmax, which gives us the index of the highest value in a NumPy array (in this case, our 5 possible outputs):
for indx, prediction in enumerate(predictions[:10]):
print(f"Original Tweet: {testing_tweets[indx][1]}")
print(f"Actual Sentiment: {testing_tweets[indx][0]}")
print(f"Predicted Sentiment: {sentiment_index[np.argmax(prediction)]}, \n")Original Tweet: "Find out how you can protect yourself and loved ones from #coronavirus?"
Actual Sentiment: Extremely Positive
Predicted Sentiment: Extremely PositiveOriginal Tweet: "Do you remember the last time you paid $2.99 a gallon for regular gas in Los
Angeles? Prices at the pump are going down. A look at how the #coronavirus is impacting prices."
Actual Sentiment: Neutral
Predicted Sentiment: PositiveOriginal Tweet: "HI TWITTER! I am a pharmacist. I sell hand sanitizer for a living! Or I do when any exists. Like masks,
it is sold the fuck out everywhere. SHOULD YOU BE WORRIED? No. Use soap. SHOULD YOU VISIT TWENTY PHARMACIES LOOKING FOR THE LAST BOTTLE? No.
Pharmacies are full of sick people."
Actual Sentiment: Extremely Negative
Predicted Sentiment: Extremely NegativeFrom here, there are a few ways we can imporve our model, the best ones being:
- Using more training data.
- Implementing custom algorithms based on our saved model.
Using more training data is a no-brainer, we just need more tweets to feed into our model.
Implementing custom algorithms is a method which most problems revolving around machine learning models can benefit from. Our network outputs predictions based on how likely it thinks each output is correct (percentage wise).
An example output, for our 5 sentiments, could look something like:
[0.08312576 0.01809235 0.89360434 0.00205717 0.00312047]Here, our network is telling us the 3rd index of the output (neutral sentiment) is 89% likely to be the correct answer. However, it also thinks the answer could be 'extemely negative' (8%). Here, we can create an algorithm which summs up both negative values, and then both positive values, to gives us an 'overall' negative and positive score. We can then in the future classify our tweets based on 3 sentiments instead of 5.
We can also say for outputs which have been classed as 'neutral', IF the network thinks it's at least 10% or more to be either negative or positive, we can change the output to be one-sentiment (index) towards the higher percentage.