Instagram Scraper - Scraping 100,000 Posts/Hr
Scripting Tools Used: Python 3, Requests, SQLite3 and Beautiful Soup
Methods here are for educational purposes only. Automated scraping on Instagram is against their ToS and is not advised.
Abstract
This Instagram scraper is one of the fastest methods of scraping instagram there is (it's also free!). With the help of Python's web scraping modules, VPNs and GraphQL, we are able to scrape over 100,000 posts per hour without interuption. With the help of fake user-agents, proxies and a powerful back-end scraping technique, we are able to by-pass Instagram's blocking security and gather data for specific hashtags or accounts.
Requirements
The following software is required for this method:
1) Python 3 (BeautifulSoup4, requests, SQLite3 (or another database) and Fake UserAgent
- pip install requests
- pip install beautifulsoup4
- pip install fake-useragent
2) Download Charles Proxy - required to get the cURL request path 3) Download Insomnia Core - used to breakdown the GraghQL query (cURL request)
Getting Request Headers Using Charles Proxy and Insomnia
Once Charles Proxy is installed, you will need to set a few settings. Firstly, go to the SSL Proxy Settings:
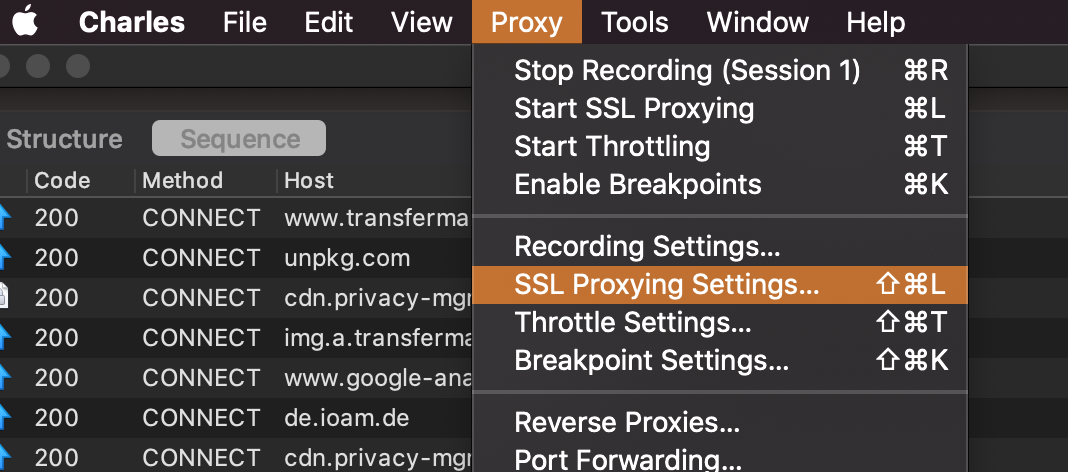
and enable SSL Proxying. Include everything (*):
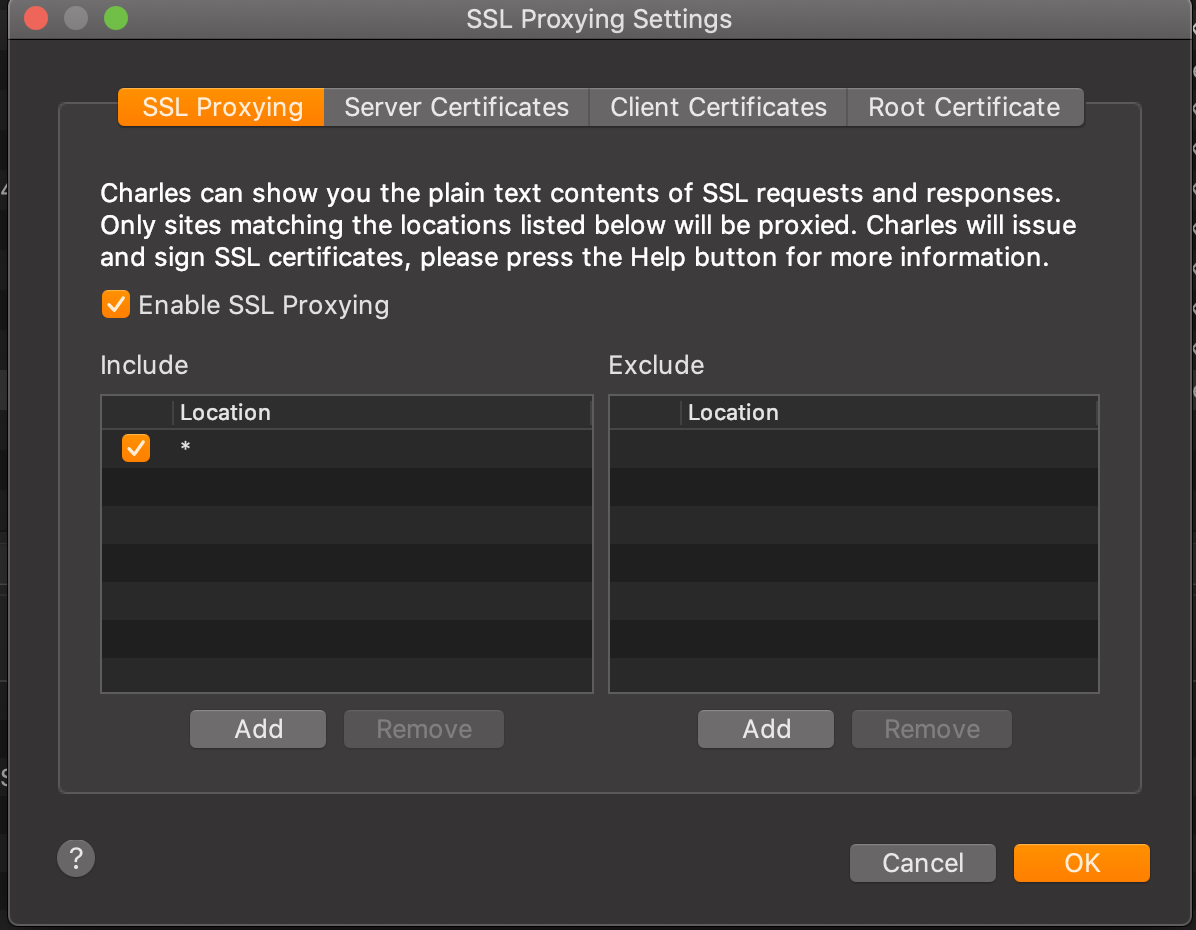
Next, we need to install the Charles root certificate. Simply go to help > SSL Proxying > Install Charles Root Certificate:
Restart your machine to proceed...
Now, Charles Proxy will be picking up all of the network requests out machine is making in real-time. We want to use this to retrieve an Instagram loading request.
With Charles Proxy running, simply load up an Instgram page, for a hashtag, on a web browser. The request should popup on Charles Proxy (filter by 'Instagram' for easier visibility).
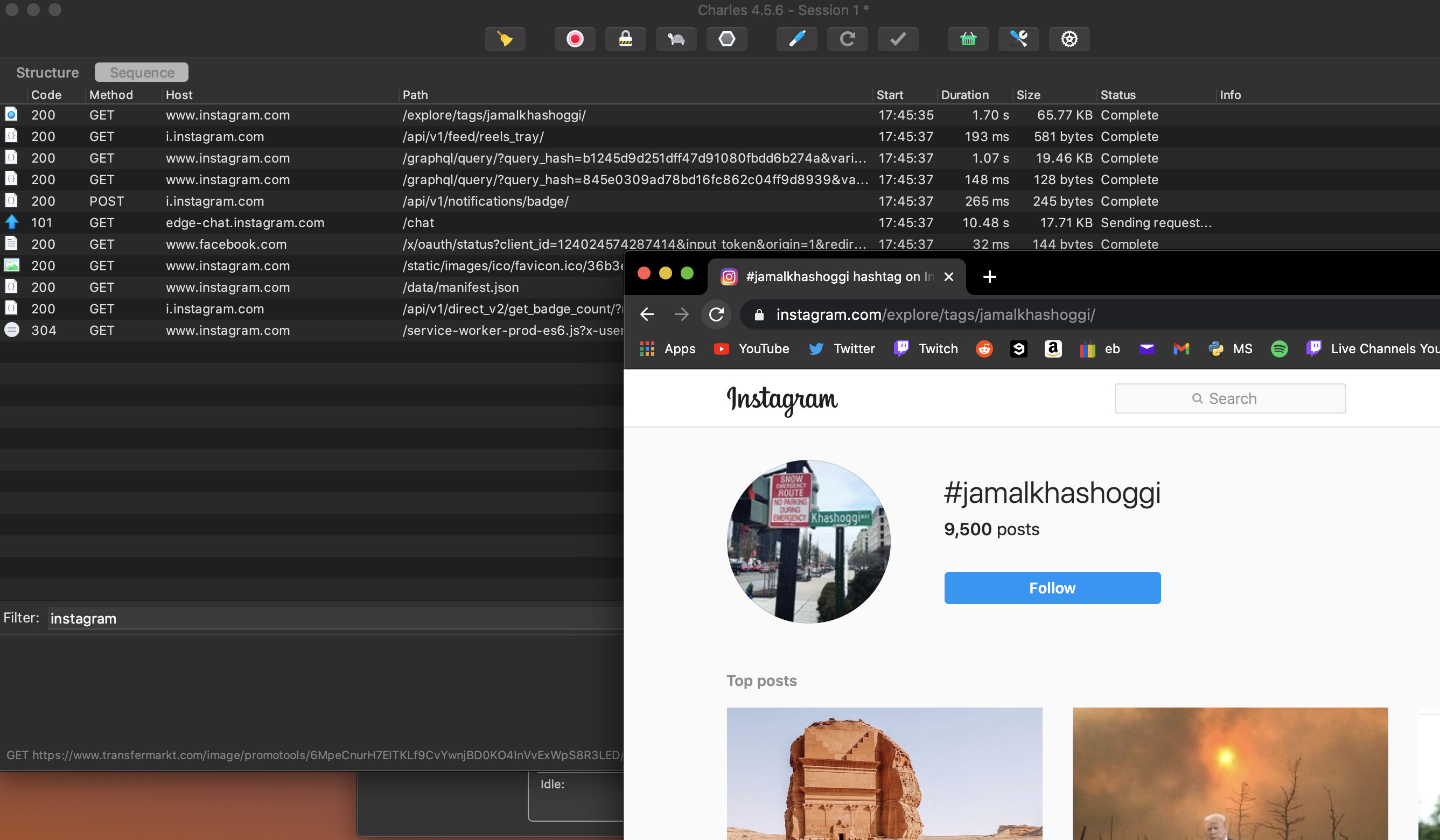
Copy the cURL request path which contains the GraphQL query.

This cURL request path contains the information we need to send through a request header in Python a little later. To view the cURL query and headers, paste the cURL path into Insomnia.
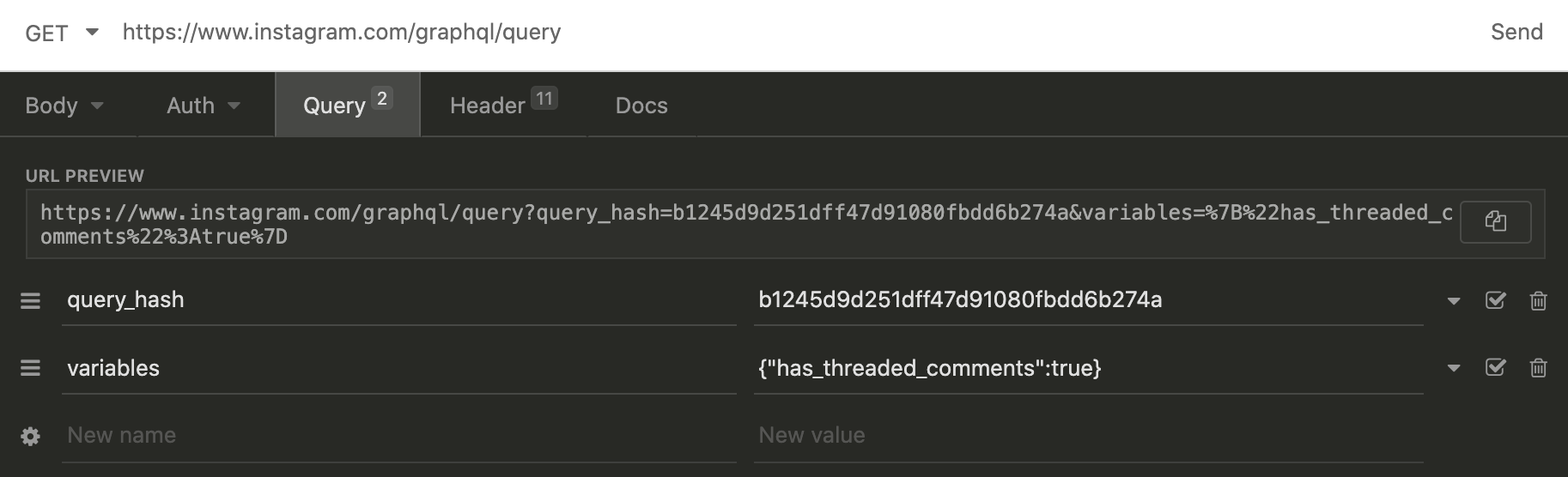
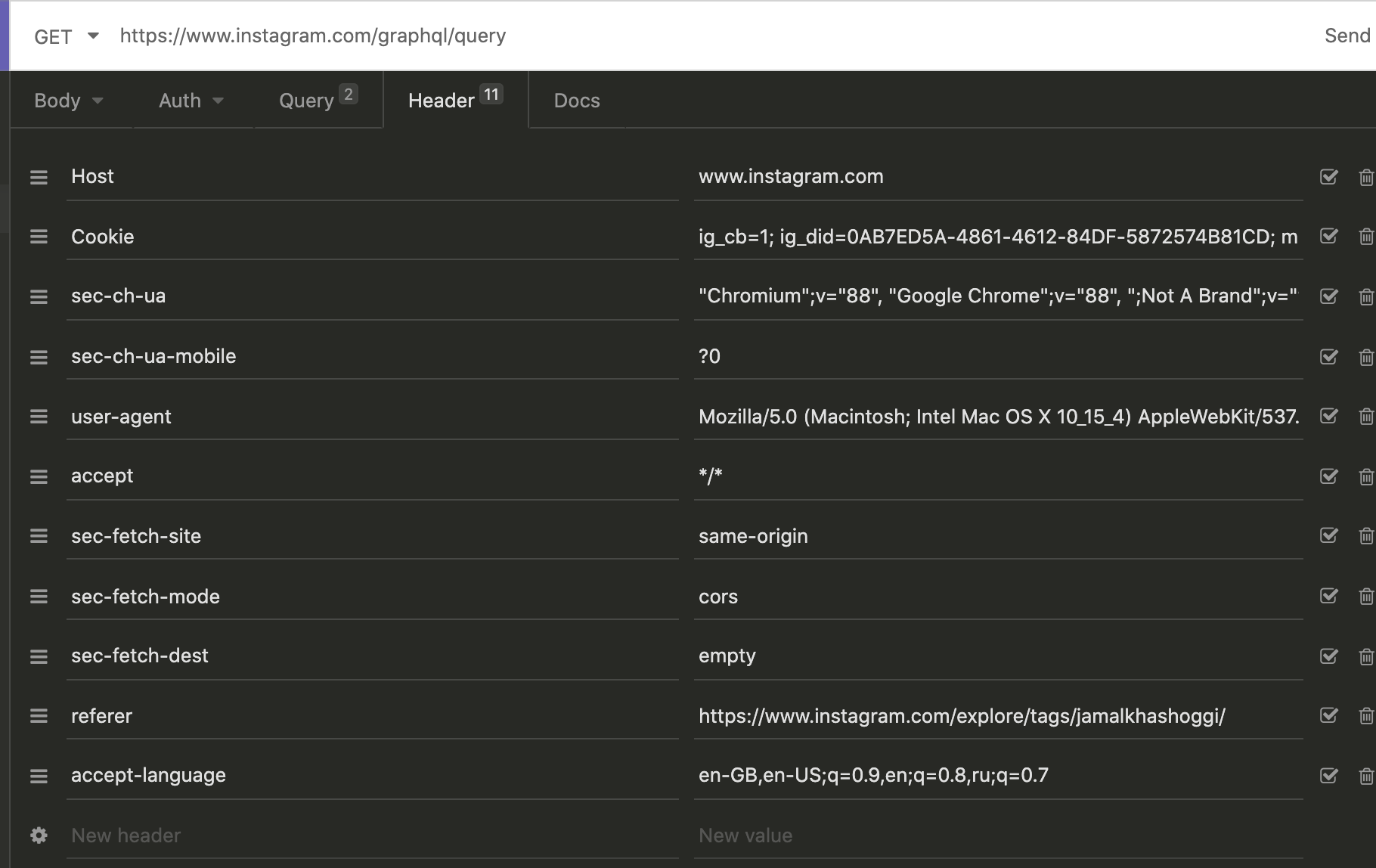
Here, we are able to see the URL, variables and header meta-data we need to make our own fully-custom requests.
Python Requests Script
We now have everything we need to create our requests script. My script is using the following imports:
import bs4 as bs
import requests
import time
from fake_useragent import UserAgent
import SQL #this is a custom file used for my SQL queriesFirsly, we want to make a separate function to setup headers and parameters. There are 3 main parameters we need to setup:
- request URL
- headers
- params(que)
The first function will give us the headers and params (que).
def get_request_params(variables):
que = {
'variables': variables
}
ua = UserAgent()
# I've edited most of these parameters to use fake data
headers = {
"Host": 'www.instagram.com',
"Cookie": """ig_cb=1; ig_did=93SEG3-4521-6433-3F3S-5; shbid=3322; ... ... "{\"54.422.53.111\": 3266}...""""",
"x-ig-www-claim": "hmac.A2894EKJaqMqtSEFf_CESFS24wsf22FASW32asfsflwPif3",
"sec-ch-ua-mobile": "?0",
"user-agent": ua.random,
"accept": "*/*",
"sec-fetch-site": "same-origin",
"sec-fetch-mode": "cors",
"sec-fetch-dest": "empty",
"referer": "https://www.instagram.com/explore/tags/{HASHTAG}/",
"accept-language": "en-GB,en-US;q=0.9,en;q=0.8,ru;q=0.7"}
return que, headersThe 'variables' variable is set in our loop, as the following:

HASHTAG - this constant is simply the hashtag on instagram we want to scrape (without the # symbol (e.g. HASHTAG = 'usa')).
first - this variable controls the amount of instagram posts we get per request. This is set to 9999 to get as many posts as possible (limited to 150 anyways).
The URL for our request is also set in our loop (this was taken from Insomnia aswell). Here, we use a f string to make the URL custom to our loop. HASHTAG and first as inserted into this URL, as well as 'end_cursor'.
url = f"""https://www.instagram.com/graphql/query?query_hash=9b448c32423f1e04347a
1703c22b2f32&variables=%7B%22tag_name%22%3A%22{HASHTAG}%22,%22first%22%3A{str(first)},
%22after%22%3A%22{end_cursor[:-2]}%3D%3D%22%7D"""end_cursor - The end_cursor is what will allow us to continue scraping the Instagram posts from the last post we scraped. Each request we do gives us one end_cursor in the JSON data, which can be found with in the request data we get while scraping.
For our script, we save the end_cursors in our database, and take the latest end_cursor for each loop. If it's a fresh scrape, we set end_cursor to nothing (""). This will allow the script to scrape from the first post of a hashtag or account.
end_cursor = data['data']['hashtag']['edge_hashtag_to_media']['page_info']['end_cursor']Putting Everything Together
Now we are ready to start our for/ While loop. At the start of our loop, we set the variables, URL and headers. With then send all these parameters into our request.
ITERATIONS = 10000
for i in range(ITERATIONS):
all_data = []
url = f"""https://www.instagram.com/graphql/query?query_hash=9b448c32423f1e04347a
1703c22b2f32&variables=%7B%22tag_name%22%3A%22{HASHTAG}%22,%22first%22%3A{str(first)},
%22after%22%3A%22{end_cursor[:-2]}%3D%3D%22%7D"""
que, headers = get_request_params(variables)
request_data = requests.get(url, headers=headers, params=que)We then check if the request was succesful, grab the end_cursor and parse our data as JSON:
if request_data.status_code == 200:
data = request_data.json()
end_cursor = data['data']['hashtag']['edge_hashtag_to_media']['page_info']['end_cursor']For our purpose here, we want to get the following data-points:
- Post Date (timestamp)
- Post URL (shortcode)
- Image of the post (thumbnail URL)
- Number of Likes
- Description
- Location of the post (if any GEO tags are available)
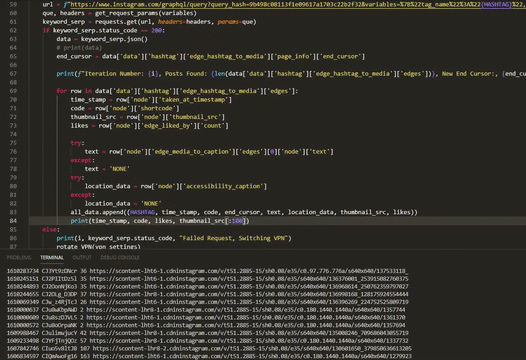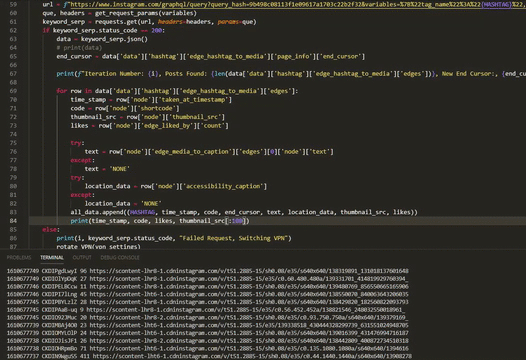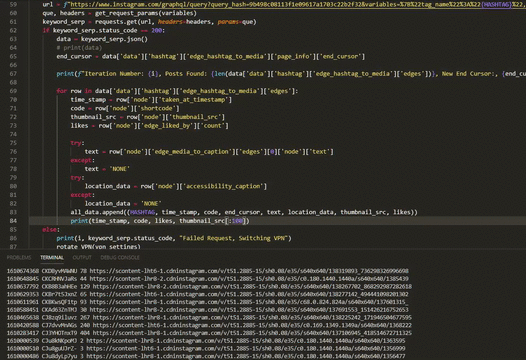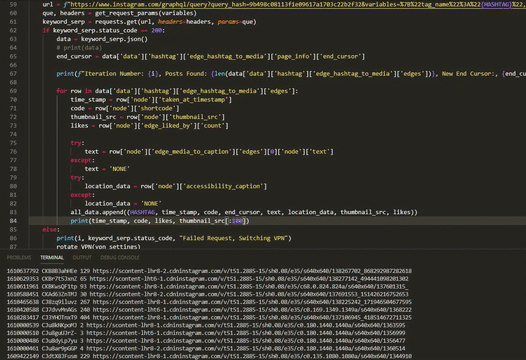
for row in data['data']['hashtag']['edge_hashtag_to_media']['edges']:
time_stamp = row['node']['taken_at_timestamp']
code = row['node']['shortcode']
thumbnail_src = row['node']['thumbnail_src']
likes = row['node']['edge_liked_by']['count']
try:
text = row['node']['edge_media_to_caption']['edges'][0]['node']['text']
except TypeError as e:
text = 'NONE'
try:
location_data = row['node']['accessibility_caption']
except TypeError as e:
location_data = 'NONE'
all_data.append((HASHTAG, time_stamp, code, end_cursor, text, location_data, thumbnail_src, likes))Handling Network Blocking
Depending on the usage of time sleeps in your script, you may get blocked every 50-500 requests. The perfect solution for this is to use NordVPN to change your network address each time you get blocked. This can be easily automated (tested on Windows machines only).
1) Download and Install Nord VPN onto your machine (a basic subscription is required).
2) Install the nordvpn switcher for Python
- pip install nordvpn-switcher
3) Add the following lines to the start of your script:
from nordvpn_switcher import initialize_VPN, rotate_VPN, terminate_VPN
vpn_settings = initialize_VPN()
rotate_VPN(vpn_settings)and when handling for data.status_code == 200, call 'rotate_VPN(vpn_settings)' in the 'else' statement.
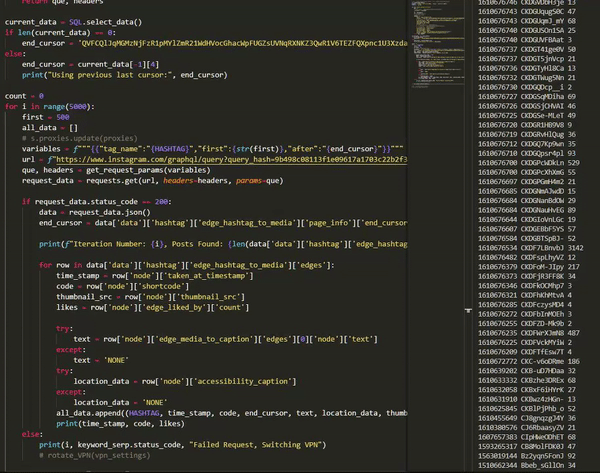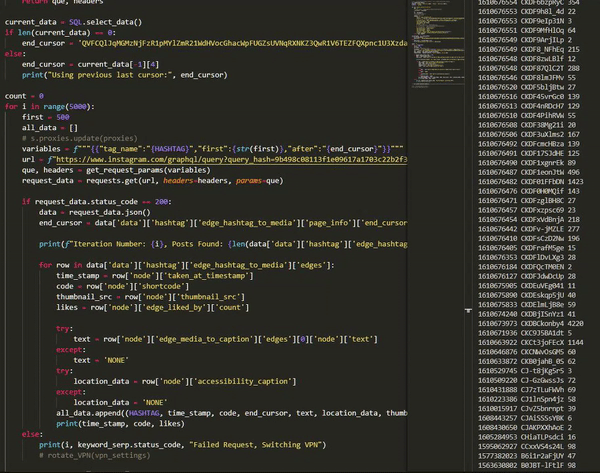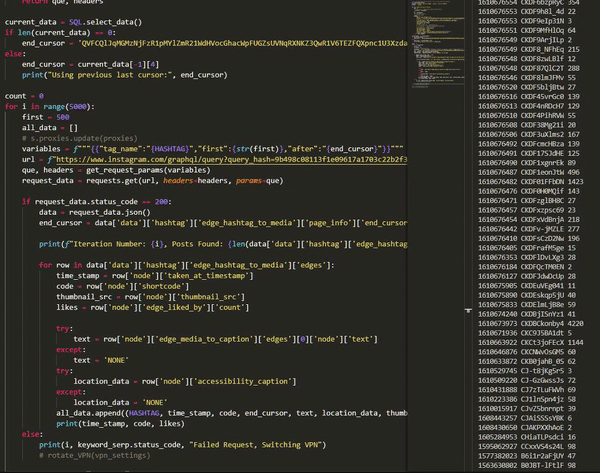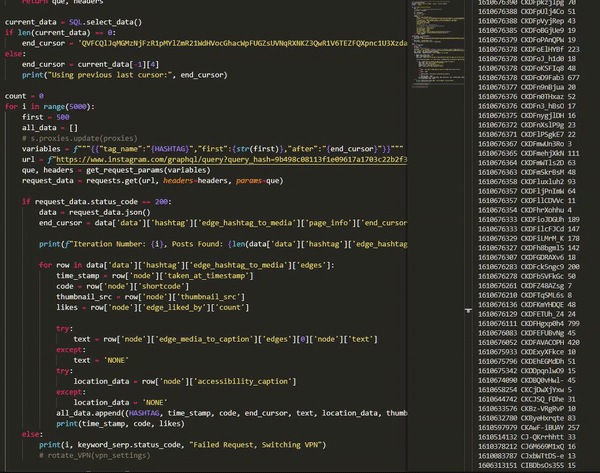
With the full script setup and running at full speed, 150 posts will be scraped every 5 seconds, resulting in over 100,000 posts per hour. It's important to add in a lot of hard-coded sleeps to avoid abusing Instagram's network.
This script can also be used to scrape specific Instagram accounts. Account ID's are required for this step, which can be found in the HTML source code of a user's account page.