Selenium Scraper - How to Scrape Any Website
Tools used: Python 3, Selenium and SQLite3
Abstract
Selenium and requests are two of the most popular methods of scraping data using Python. Selenium using a WebDriver protocol to control a web driver (browser).
The advantage of uses Selenium is the user can set commands to interact with dynamic elements within the webpage, render JavaScript faster and avoid automated website security by simulating a human visit.
Here, we will be scraping off of a graph on pricecharting.com:
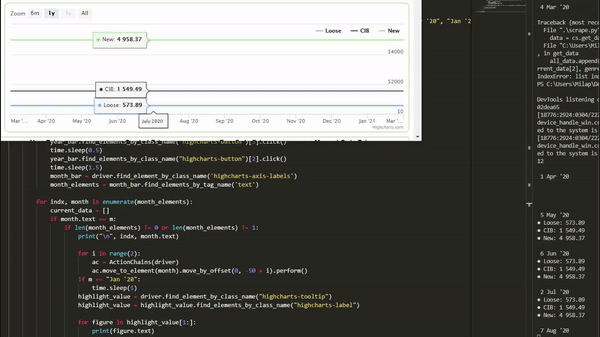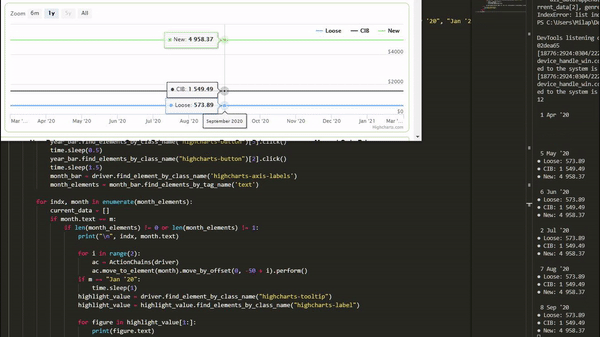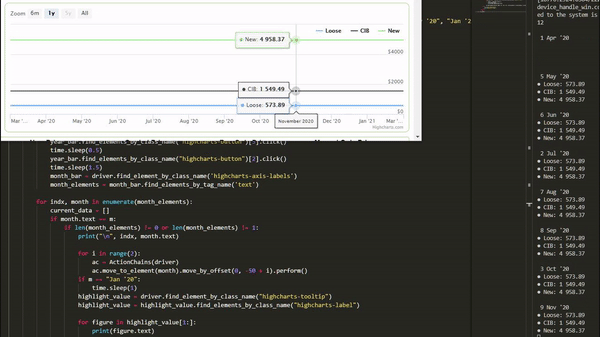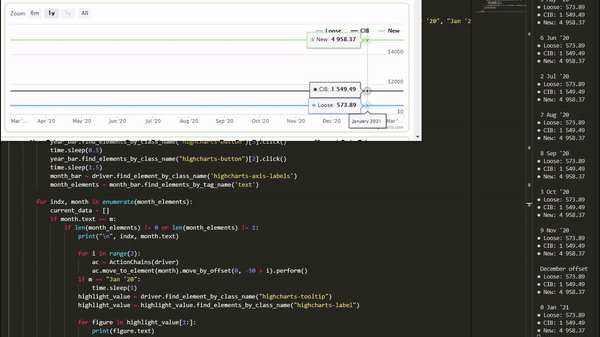
Requirements
There are a few Python 3 packges requried for this scrape:
- pip install selenium - Selenium has the functions we need to render, interact with and scrape through a Chrome driver (browser).
- pip install selenium - Selenium has the functions we need to render, interact with and scrape through a Chrome driver (browser).
Go to Chromium and download the Chrome driver. Select the version according to your regular Google Chrome browser.
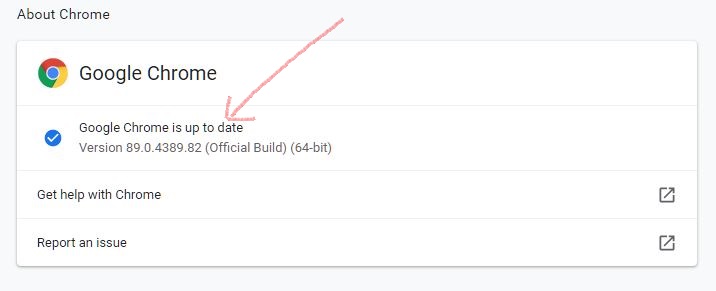
You can check which version you need by going to Chrome's Help > 'About Google Chrome' page
Setup
Once downloaded, put the chromedriver in the local directory where your Python script will sit. You can also add it to the system PATH to be saved for future uses.
Here, we can assign our driver to a variable using os.getcwd(), and import the Selenium functions we are going to use for our script.
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.action_chains import ActionChains
import time
import os
import csv
import sqlite3driver_path = os.getcwd() + "\chromedriver"Next, we can make a function which initiates our driver. Here, we can set any driver options we will need and point executable_path to our driver
def int_driver():
chrome_options = Options()
chrome_options.add_argument("--start-maximized")
driver = webdriver.Chrome(options=chrome_options, executable_path=driver_path)
return driverand a simple function which takes and loads our url(s)
def start(driver, url):
driver.get(url)
return driverMain Script
Now, we can import a list of URLs which point to video game pages on PriceCharting. I have curated this list from a previous scrape. We will be getting data for all the games on this list. We can create our SQLite3 database table while we are at it:
SQL.create_data_table()
with open('input.csv', newline='') as f:
reader = csv.reader(f)
input_data = list(reader)Initate the chrome driver using our function and assign it to a variable. This will open up the Google Chrome (driver) window.
driver = cs.int_driver()Now let's start our loop. The input data (URLs) I'm using is formatted as:
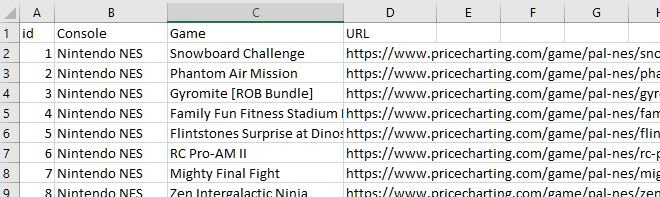
# using [1:] to skip the first row with titles
for _id, console, game, url in input_data[1:]:
driver = cs.start(driver, url)
data = get_data(driver, console, game, url)Now we can make our get_data function. First of all, let's get some extra data outside of the graph. Here, we are getting the genre and release date for the game, in the description list.
meta_data = driver.find_element_by_id('full_details')
try:
for td in meta_data.find_elements_by_tag_name('td'):
if td.get_attribute('itemprop') == 'genre':
genre = td.text
if td.get_attribute('itemprop') == 'datePublished':
release_date = td.text
break
except TypeError as e:
# not every page will have a genre and release date listed
# so we can handle for the 'None' type object which will be returned
print(str(e))
genre = 'UNKNOWN'
release_date = 'UNKNOWN'Now, we need to toggle a few options on the graph:
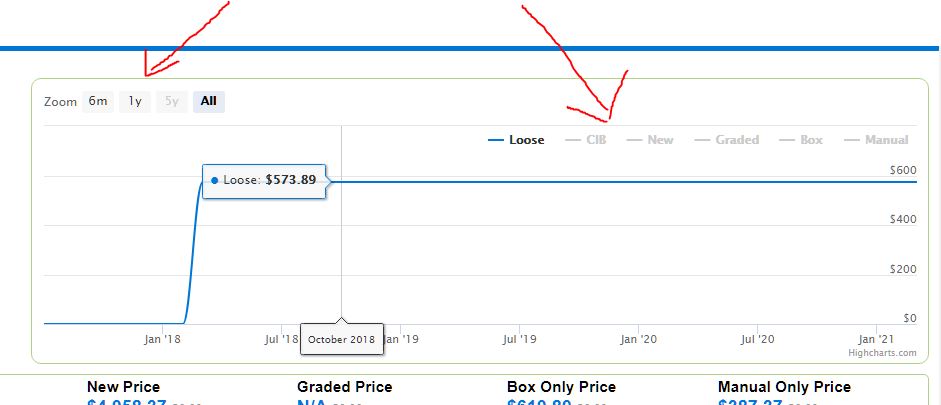
We can find the category buttons using its class name "highcharts-legend-item" and then the date divider with the class name 'highcharts-range-selector-group'.
year_bar = driver.find_element_by_class_name("highcharts-range-selector-group")
chart_legend_split = driver.find_elements_by_class_name("highcharts-legend-item")We also need to initiate our data list and note down the months (X axis tags) we want to scrape.
all_data = []
axis_bar = ["Feb '20", "Mar '20", "Apr '20", "May '20", "Jun '20", "Jul '20",
"Aug '20", "Sep '20", "Oct '20", "Nov '20", "Jan '21", "Jan '20"]
CLICK_LOAD_WAIT = 0.5Toggle each option in the category list:
for legend_item in chart_legend_split[1:]:
legend_item.find_element_by_tag_name('text').click()
# Wait a short amount of time in between clicks to avoid clashes
time.sleep(CLICK_LOAD_WAIT)Now we need to get the labels on the X axis of the graph. Here, we will cycle through each one. We need some additional handling for the earliest date (Jan 2020) as it wont be in the current date toggle we have.
Here, if we are at 'Jan 20' in our cycle, we click on the date divers we need, and then get that piece of data.
for m in axis_bar:
if m == "Jan '20":
year_bar.find_elements_by_class_name("highcharts-button")[3].click()
time.sleep(CLICK_LOAD_WAIT)
year_bar.find_elements_by_class_name("highcharts-button")[2].click()
time.sleep(CLICK_LOAD_WAIT)
month_bar = driver.find_element_by_class_name('highcharts-axis-labels')
month_elements = month_bar.find_elements_by_tag_name('text')Within the current loop, we can initiate another loop to go through each element on the X axis. Once we find a match, we can simulate a mouse hover above the axis to render that piece of data. Here, we can used ActionChains and the move_to_element method. We offset the Y axis to move our 'cursor' higher up, above the month label and onto the graph itself, rendering the data.
for indx, month in enumerate(month_elements):
current_data = []
if month.text == m:
for i in range(2):
ac = ActionChains(driver)
ac.move_to_element(month).move_by_offset(0, -50 + i).perform()While the data is loaded, we can grab the elements we need using:
highlight_value = driver.find_element_by_class_name("highcharts-tooltip")
highlight_value = highlight_value.find_elements_by_class_name("highcharts-label")
# we want to get each piece of data in the label (all pricing categories)
for figure in highlight_value[1:]:
current_data.append(figure.text)
all_data.append((console, game, url, month.text, current_data[0], current_data[1], current_data[2], genre, release_date))For the particular date toggles we are using (monthly), 'Dec 20' doesn't appear as a label in the X axis, which means our script will not find a match and skip it, even though the data can still be seen on the graph hover after November
To handle for this, we can use the coordinates for Nov 20 instead, and offset our cursor through the X axis. This will allow us to accurately hover over the december data.
if m == "Nov '20":
ac.move_to_element(month).move_by_offset(70, -50).click().perform()
highlight_value = driver.find_element_by_class_name("highcharts-tooltip")
highlight_value = highlight_value.find_elements_by_class_name("highcharts-label")Finally, we can append all our data, return as a list, and insert the data into our SQL table (back in our initial for loop.
all_data.append((console, game, url, "Dec '20", current_data[0], current_data[1], current_data[2], genre, release_date))
return all_dataSQL.insert_data(data)SQL statements used:
def create_data_table():
conn = sqlite3.connect('price_charting_data.db')
c = conn.cursor()
c.execute("""CREATE TABLE IF NOT EXISTS chart_data(id integer primary key,
console TEXT, game TEXT, url TEXT, month TEXT, loose TEXT, CIB TEXT, NEW TEXT, genre TEXT, release_date TEXT
)""")
c.close()
conn.close()def insert_data(insert_data):
conn = sqlite3.connect('price_charting_data.db')
c = conn.cursor()
insert_statement = """INSERT INTO chart_data
(console, game, url, month, loose, CIB, NEW, genre, release_date)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)"""
c.executemany(insert_statement, insert_data)
conn.commit()
c.close()
conn.close()def select_data():
conn = sqlite3.connect('price_charting_data.db')
c = conn.cursor()
c.execute("SELECT * FROM chart_data")
rows = c.fetchall()
c.close()
conn.close()
return rows